VirtualBox固定サイズディスクの拡張
※忘れてしまうので自分用環境向けメモ(LVMや暗号化ボリュームでない場合)
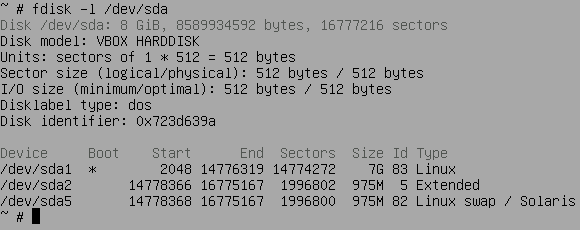
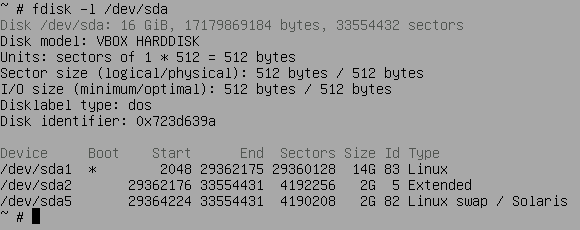
- 新しいディスクを作成して追加でアタッチ。CDから起動。
dd if=/dev/sda of=/dev/sdb conv=noerror,syncで丸ごとコピー。なお、結果が標準エラー出力に
w+p records in w+p records out
のように出てくるが、wは「whole blocks」、pは「partial blocks」でブロックサイズより転送データが少ないとき。参考:dd - ArchWiki、dd invocation (GNU Coreutils 9.0)。
fdisk /dev/sdbでパーティションテーブルを変更。なお、fdisk -l /dev/sdbでpコマンドと同じ結果を出力。
p(パーティションテーブル表示) d(swapパーティション削除) d(swapが入っていた拡張パーティション削除) d(ext4パーティション削除) n(ext4パーティション作成。セクタサイズ512バイトで必要サイズとなるEnd位置を指定。ext4 signatureは消さない。) n(swapを入れる拡張パーティション作成) n(swapパーティション作成) t(swapパーティションのタイプ82を指定) a(ext4パーティションにブートフラグを立てる) w(変更を書き込んで終了)
e2fsck -f /dev/sdb1でext4ファイルシステムをチェックしてから、resize2fs /dev/sdb1でext4ファイルシステムを拡張。mkswap /dev/sdb5でswap領域を作る。blkidでext4とswapのUUIDを調べ、/etc/fstabと/etc/initramfs-tools/conf.d/resumeのUUID(特にswap)を更新し、update-initramfs -u。このとき/etc/initramfs-tools/conf.d/resume.origのように古いファイルを残さないこと。/etc/initramfs-tools/conf.d/内の全てのファイルが読まれて警告の原因になる。ejectでCDを取り、シャットダウンしてから古いディスクをデタッチし、新しいディスクを「ポート0」に。- (この操作は不要かも)再度CDから起動して
grub-install /dev/sda。ejectでCDを取り、再起動。
CVE-2022-0847(Dirty Pipe)について
Abstract[1]
Linuxカーネルにバージョン5.8から存在し、任意の読み取り専用ファイル(のページキャッシュ)を上書き可能な脆弱性です。 非特権プロセスがrootプロセスにコード注入可能なため、権限昇格につながります。 Dirty COW (CVE-2016-5195)に似た脆弱性ですが、exploitがより簡単です。 Linuxカーネル5.16.11, 5.15.25, 5.10.102で修正されています。早急にアップデートすべきです。
Description[4]
Linuxカーネル内の関数copy_page_to_iter_pipe()及びpush_pipe()内で、確保したpipe_buffer構造体のflagsメンバが適切に初期化されずに古い値のまま残る欠陥が見つかりました。
非特権ユーザがこの欠陥を使って、読み取り専用ファイルに対応したページキャッシュに書き込むことで権限昇格が可能になります。
脆弱性の原因
文献[2]が詳しいです。その後で文献[3]を読めば、本家の状況を理解することができると思います。 脆弱性が生まれるのに複数の要因が重なっています。すぐに思いつくのは以下のとおりですが、探せばまだあるかもしれません:
- パイプにリングバッファを採用し、循環して利用していること
- マージ機構により、同一ページに追加していく実装であること
splice()で読み込んだページキャッシュを、リングバッファから直接参照していること(zero-copy)- 問題の関数が導入された当初から初期化漏れがあったこと
- ポインタ比較をやめて
PIPE_BUF_FLAG_CAN_MERGEフラグを導入したこと
脆弱性の修正コード[5]
問題のファイルはカーネルのlib/iov_iter.cです。
関数copy_page_to_iter_pipe()及びpush_pipe()で新しいpipe_bufferをアロケートした後にflagsメンバのフラグクリアが抜けており、これを補っています。
diff --git a/lib/iov_iter.c b/lib/iov_iter.c index b0e0acdf96c15..6dd5330f7a995 100644 --- a/lib/iov_iter.c +++ b/lib/iov_iter.c @@ -414,6 +414,7 @@ static size_t copy_page_to_iter_pipe(struct page *page, size_t offset, size_t by return 0; buf->ops = &page_cache_pipe_buf_ops; + buf->flags = 0; get_page(page); buf->page = page; buf->offset = offset; @@ -577,6 +578,7 @@ static size_t push_pipe(struct iov_iter *i, size_t size, break; buf->ops = &default_pipe_buf_ops; + buf->flags = 0; buf->page = page; buf->offset = 0; buf->len = min_t(ssize_t, left, PAGE_SIZE);
まず関数copy_page_to_iter_pipe()です。
static size_t copy_page_to_iter_pipe(struct page *page, size_t offset, size_t bytes, struct iov_iter *i) { struct pipe_inode_info *pipe = i->pipe; struct pipe_buffer *buf; unsigned int p_tail = pipe->tail; unsigned int p_mask = pipe->ring_size - 1; unsigned int i_head = i->head; size_t off; if (unlikely(bytes > i->count)) bytes = i->count; if (unlikely(!bytes)) return 0; if (!sanity(i)) return 0; off = i->iov_offset; buf = &pipe->bufs[i_head & p_mask]; if (off) { if (offset == off && buf->page == page) { /* merge with the last one */ buf->len += bytes; i->iov_offset += bytes; goto out; } i_head++; buf = &pipe->bufs[i_head & p_mask]; } if (pipe_full(i_head, p_tail, pipe->max_usage)) return 0; buf->ops = &page_cache_pipe_buf_ops; buf->flags = 0; /* フラグ PIPE_BUF_FLAG_CAN_MERGE がセットされていてもクリアする */ get_page(page); buf->page = page; buf->offset = offset; buf->len = bytes; pipe->head = i_head + 1; i->iov_offset = offset + bytes; i->head = i_head; out: i->count -= bytes; return bytes; }
次に関数push_pipe()です。
static size_t push_pipe(struct iov_iter *i, size_t size, int *iter_headp, size_t *offp) { struct pipe_inode_info *pipe = i->pipe; unsigned int p_tail = pipe->tail; unsigned int p_mask = pipe->ring_size - 1; unsigned int iter_head; size_t off; ssize_t left; if (unlikely(size > i->count)) size = i->count; if (unlikely(!size)) return 0; left = size; data_start(i, &iter_head, &off); *iter_headp = iter_head; *offp = off; if (off) { left -= PAGE_SIZE - off; if (left <= 0) { pipe->bufs[iter_head & p_mask].len += size; return size; } pipe->bufs[iter_head & p_mask].len = PAGE_SIZE; iter_head++; } while (!pipe_full(iter_head, p_tail, pipe->max_usage)) { struct pipe_buffer *buf = &pipe->bufs[iter_head & p_mask]; struct page *page = alloc_page(GFP_USER); if (!page) break; buf->ops = &default_pipe_buf_ops; buf->flags = 0; /* フラグ PIPE_BUF_FLAG_CAN_MERGE がセットされていてもクリアする */ buf->page = page; buf->offset = 0; buf->len = min_t(ssize_t, left, PAGE_SIZE); left -= buf->len; iter_head++; pipe->head = iter_head; if (left == 0) return size; } return size - left; }
exploitが成功する条件[1]
条件はかなり緩く、攻撃者がPoC相当のコードを走らせることができたら、簡単にroot権限を取ることができます。早急にアップデートすべきです。
例えば/etc/passwdのページキャッシュを書き換えた直後にsuコマンドを打つことでroot権限を奪われてしまいます。
攻撃対象ファイルに書き込むプロセスも(非特権プロセスで書き込むことすら)不要ですし、タイミング条件もありませんし、ほとんど任意の場所に任意のデータを書き込むことができます。 制限としては以下のとおりです:
- 攻撃対象ファイルの読み取りパーミッションがあること(ページキャッシュを読み込んでパイプに
splice()するために必要) - オフセットがページ境界にないこと(少なくとも1バイトはパイプに
splice()する必要がある) - 書き込む内容がページ境界をまたがないこと(あぶれた部分のために新しいバッファページが作られるため)
- 攻撃対象ファイルはリサイズできない(パイプのページ管理バグを利用するので書き込みサイズが分からない)
カーネルからはページキャッシュが常に書き込み可能なうえパイプへの書き込みにはパーミッションチェックが無いため、攻撃にはファイルの書き込みパーミッションすら不要でイミュータブルなファイルでも攻撃対象になり得ます。
ただし、これはページキャッシュを書き換える脆弱性なので、ページキャッシュが更新された(dirtyである)とカーネルが判定しなければ永続化しません。 逆に言えば、再起動したりカーネルがメモリ不足などの理由でページキャッシュを捨ててしまえば(reclaim)痕跡が残らなくなるので、注意が必要です。
感想
本家[1]は、不具合の報告から端を発して、ユーザーランドそしてカーネルへと原因追及が進み、かなり重大な権限昇格の脆弱性を発見するまでの過程が記されています。
その途中で、ファイルの破損箇所のバイト列を検証したりgit bisectを活用して原因コミットを絞り込んだりと非常に参考になりました。
さらにカーネルチームにパッチを送り、どのような過程で重大な脆弱性が生まれたのかまで調査するなど、しっかりと取り組んだ感じがします。
参考文献
- The Dirty Pipe Vulnerability — The Dirty Pipe Vulnerability documentation - 本家
- 20分で分かるDirty Pipe(CVE-2022-0847) - knqyf263's blog - 詳しい解説
- spliceを使って高速・省メモリでGzipからZIPを作る - knqyf263's blog - 文献[2]を読んだ後の落穂拾いに
- CVE - CVE-2022-0847 - CVE
- kernel/git/torvalds/linux.git - Linux kernel source tree - 脆弱性の修正コミット
- CVE-2022-0847 - DSA-5092-1
リスト初期化とオーバーロード解決
この記事ではC++11で追加されたリスト初期化について、今更ながらまとめてみた。ソースはN3690。
uniform initialization、list initialization
これまでは初期化という同一のセマンティクスを実現するのに、ばらばらで不統一なシンタックスを使っていた。
int i = 2013; char s[] = { 'A', 'p', 'p', 'l', 'e' }; struct X { int i; char s[ 4 ]; } x = { 16, { 'a', 'b', 'c', '\0' } }; std::vector< double > v( 8, 1.0 );
C++11で提案されたuniform initializationは、変数宣言など(後述)で波カッコリスト{…}を用いる統一したシンタックスで、初期化リスト{…}による初期化のセマンティクスを実現するもの。これにより、型に依存しないシンタックスが必然的に求められるテンプレートにおいて、初期化の記述性を向上させることができる。
int i = { 2013 }; char s[] = { 'A', 'p', 'p', 'l', 'e' }; struct X { int i; char s[ 4 ]; } x = { 16, { 'a', 'b', 'c', '\0' } }; std::vector< double > v{ 8, 1.0 };
初期化リスト{…}による初期化、といっても「初期化される型」と「初期化リストの内容」に応じて具体的な振る舞いが異なるため、その詳細について調べてみた。なお、初期化リストの要素にはリテラル・変数・関数を含む任意の式を使用でき、変数のstorage durationによらない(8.5p2)。
初期化にまつわる用語
- ゼロ初期化(zero-initialization、8.5p6):
- デフォルト初期化(default-initialization、8.5p7):
- クラス…デフォルトコンストラクタが呼ばれる
- 配列…各要素をデフォルト初期化
- それ以外…何もしない
- 値初期化(value-initialization、8.5p8):
- コピーによる初期化(copy-initialization、8.5p15):
- T x = a; の形式(代入形式)
- 関数への実引数渡し
- 関数からの返却値
- 例外のスロー
- 例外のキャッチ
- 集約メンバの初期化
- 直接的な初期化(direct-initialization、8.5p16):
- T x(a); の形式(関数形式)
- T x{a}; の形式(波カッコ形式)
- new式
- static_cast式
- 関数表記の型変換
- 基底・メンバ初期化子
std::initializer_listと初期化リストコンストラクタ
std::initializer_listは、ヘッダ
namespace std { template<class E> class initializer_list { public: typedef E value_type; typedef const E& reference; typedef const E& const_reference; typedef size_t size_type; typedef const E* iterator; typedef const E* const_iterator; constexpr initializer_list() noexcept; constexpr size_t size() const noexcept; // number of elements constexpr const E* begin() const noexcept; // first element constexpr const E* end() const noexcept; // one past the last element }; // 18.9.3 initializer list range access template<class E> constexpr const E* begin(initializer_list<E> il) noexcept; template<class E> constexpr const E* end(initializer_list<E> il) noexcept; }
初期化リストコンストラクタ(initializer-list constructor)とは、第一引数がstd::initializer_list< E >(又はそのリファレンス)であり、その他の仮引数がないか、すべてデフォルト実引数が設定されているコンストラクタのこと(8.5.4p2)。
これが呼び出されると、初期化リストの内容・サイズでconst E型の固定長配列が作られて、その配列を参照するようにstd::initializer_list< E >が構築される(8.5.4p5)。作られる配列は一時オブジェクト扱いだが、std::initializer_list< E >をこれで初期化することで、配列の寿命(lifetime)はリファレンスにバインドされた時とまったく同じになる(8.5.4p6)。
集約
集約(aggregate)とは、以下のこと(8.5.1p1)であり、C言語で配列や構造体の初期化に使われた波カッコ初期化の文法が、ここからC++に残った。
- 配列、又は
- ユーザ定義のコンストラクタ、private又はprotectedな非静的データメンバ、基底クラス、仮想関数を一切含まないクラス
集約を初期化リストで初期化する場合、集約のメンバが添字の増加順又はメンバの宣言順に、初期化リストの要素によって(コピーによる)初期化される(8.5.1p2)。初期化リストに更に初期化リストが含まれている場合は、対応するメンバが集約であれば、これに対して再帰的にこのルールを適用する(8.5.1p2)。
サイズ不明の配列を初期化リストで初期化する場合、配列のサイズは初期化リストのそれになる。空リストによる初期化はできない(8.5.1p3)。静的データメンバ及び匿名ビットフィールドは、集約の初期化では無視される(8.5.1p4)。
リスト初期化
リスト初期化は、直接的な初期化・コピーによる初期化のどちらのコンテキストでも可能(8.5.4p1)で、次の場面で使うことができる:
- 変数定義における初期化子として
- new式における初期化子として
- return文において
- range-based for文において…for ( auto i : ここ )
- 関数に渡す実引数として
- 添字として
- コンストラクタ呼び出しへ渡す実引数として
- 非静的データメンバの初期化子として
- コンストラクタ内のメンバ初期化子の中で
- 代入文の右辺で
型Tのオブジェクト又はリファレンスのリスト初期化は以下の手順で行われる(8.5.4p3):
- Tが集約である場合、上記のとおり集約の初期化が行われる
- 空リストによる初期化で、かつTがデフォルトコンストラクタを持つクラスの場合、オブジェクトは値初期化される(後述)
- Tがstd::initializer_list< E >の特殊化である場合、initializer_listのprvalueが生成され、オブジェクトの初期化に使われる
- Tがクラスの場合、適用可能なコンストラクタの中からオーバーロード解決を通して最適なものが選ばれる(後述)
- 初期化リストに要素が1つだけある場合、オブジェクト又はリファレンスはその要素で初期化される
- Tが参照型の場合、Tが参照している型のprvalueな一時オブジェクトが生成・初期化され、リファレンスはその一時オブジェクトにバインドされる
- 空リストによる初期化の場合、オブジェクトは値初期化される
- これらの条件を上から順に適用していき、どれにも該当しない場合、プログラムはill-formedである
オーバーロード解決
集約でないクラスTをリスト初期化すると、呼び出すコンストラクタを選択するため、オーバーロード解決が2段階で行われる(13.3.1.7p1):
- まず、初期化リスト全体を単一の実引数とみなし、Tの初期化リストコンストラクタを候補関数とする。
- 最適な(viable)初期化リストコンストラクタが見つからなかった場合、初期化リストの各要素を実引数とみなし、Tの全てのコンストラクタを候補関数として再度オーバーロード解決を試みる。
※ただし、空リストによる初期化で、かつTがデフォルトコンストラクタを持っている場合、①は省略される。
リスト初期化で呼び出されるコンストラクタについて、以下のサンプルコードで実験してみる:
#include <iostream> #include <initializer_list> #include <string> class A { public: A() { std::cout << "A::A()" << std::endl; } A( std::initializer_list< int > ) { std::cout << "A::A( initializer_list< int > )" << std::endl; } A( std::initializer_list< std::string > ) { std::cout << "A::A( initializer_list< string > )" << std::endl; } A( int ) { std::cout << "A::A( int )" << std::endl; } A( int, std::string ) { std::cout << "A::A( int, string )" << std::endl; } A( double ) { std::cout << "A::A( double )" << std::endl; } A( double, std::string ) { std::cout << "A::A( double, string )" << std::endl; } }; class B { public: B() { std::cout << "B::B()" << std::endl; } B( std::initializer_list< int > ) { std::cout << "B::B( initializer_list< int > )" << std::endl; } // NOT declared // B( std::initializer_list< std::string > ); B( int ) { std::cout << "B::B( int )" << std::endl; } B( int, std::string ) { std::cout << "B::B( int, string )" << std::endl; } B( double ) { std::cout << "B::B( double )" << std::endl; } B( double, std::string ) { std::cout << "B::B( double, string )" << std::endl; } }; class C { public: // NOT declared // C(); C( std::initializer_list< int > ) { std::cout << "C::C( initializer_list< int > )" << std::endl; } C( std::initializer_list< std::string > ) { std::cout << "C::C( initializer_list< string > )" << std::endl; } C( int ) { std::cout << "C::C( int )" << std::endl; } C( int, std::string ) { std::cout << "C::C( int, string )" << std::endl; } C( double ) { std::cout << "C::C( double )" << std::endl; } C( double, std::string ) { std::cout << "C::C( double, string )" << std::endl; } }; class D { public: // NOT declared // D(); D( std::initializer_list< int > ) { std::cout << "D::D( initializer_list< int > )" << std::endl; } // NOT declared // D( std::initializer_list< std::string > ); D( int ) { std::cout << "D::D( int )" << std::endl; } D( int, std::string ) { std::cout << "D::D( int, string )" << std::endl; } D( double ) { std::cout << "D::D( double )" << std::endl; } D( double, std::string ) { std::cout << "D::D( double, string )" << std::endl; } }; int main() { A a0 {}; A a1 { 1, 2, 3 }; A a2 { "hoge", "piyo", "fuga" }; A a3 { 100 }; // A( initializer_list< int > ) A a4 { 100, "hello" }; A a5 { 3.14 }; // A( initializer_list< int > ) warning: narrowing: (double) -> (int) A a6 { 3.14, "hello" }; std::cout << "---" << std::endl; B b0 {}; B b1 { 1, 2, 3 }; // B b2 { "hoge", "piyo", "fuga" }; // error: invalid conversion: (const char*) -> (int) B b3 { 100 }; B b4 { 100, "hello" }; B b5 { 3.14 }; B b6 { 3.14, "hello" }; std::cout << "---" << std::endl; // C c0 {}; // error: ambiguous overload resolution: C( initializer_list< int > ) or C( initializer_list< string > ) C c1 { 1, 2, 3 }; C c2 { "hoge", "piyo", "fuga" }; C c3 { 100 }; C c4 { 100, "hello" }; C c5 { 3.14 }; C c6 { 3.14, "hello" }; std::cout << "---" << std::endl; D d0 {}; // D( initializer_list< int > ) D d1 { 1, 2, 3 }; // D d2 { "hoge", "piyo", "fuga" }; D d3 { 100 }; D d4 { 100, "hello" }; D d5 { 3.14 }; D d6 { 3.14, "hello" }; return 0; }
実行結果は以下のとおり(GCC4.8.1)で、d0でD( initializer_list< int > )が呼ばれており、空リスト初期化は必ずしもデフォルトコンストラクタ呼び出しにならない。また、c0のように、初期化リストコンストラクタがinitializer_list< T >の異なる特殊化でオーバーロードされていたら、空リストに対してオーバーロード解決できない。
なお、リスト初期化にもかかわらずa5、b5、c5、d5でdouble→intのナローイングが起こっているのに、なぜかエラーではなく警告が出た。GCCの仕様なのか、よく分からない…
A::A() A::A( initializer_list< int > ) A::A( initializer_list< string > ) A::A( initializer_list< int > ) A::A( int, string ) A::A( initializer_list< int > ) A::A( double, string ) --- B::B() B::B( initializer_list< int > ) B::B( initializer_list< int > ) B::B( int, string ) B::B( initializer_list< int > ) B::B( double, string ) --- C::C( initializer_list< int > ) C::C( initializer_list< string > ) C::C( initializer_list< int > ) C::C( int, string ) C::C( initializer_list< int > ) C::C( double, string ) --- D::D( initializer_list< int > ) D::D( initializer_list< int > ) D::D( initializer_list< int > ) D::D( int, string ) D::D( initializer_list< int > ) D::D( double, string )
ナローイング
ナローイング(narrowing conversion)とは以下の暗黙の型変換(8.5.4p7)を指す:
- 浮動小数点型→整数型
- long double→double or float、double→float(変換元が定数で、その値が変換後の型で表現できる場合を除く)
- 整数型 or unscoped列挙型→浮動小数点型(変換元が定数で、その値が変換後の型にぴったりはまり、元の型に戻すとオリジナルの値を再現する場合を除く)
- 整数型 or unscoped列挙型→表現できる範囲のより狭い整数型(変換元が定数で、整数昇格後の値が変換後の型にぴったりはまる場合を除く)
リスト初期化ではナローイングは禁止(8.5.1p2、8.5.4.p3、8.5.4p5)されている。C++03までは集約の初期化でナローイングが認められていたが、C++11でこの後方互換性を破棄した。以下はN3690からの引用:
int x = 999; // x is not a constant expression const int y = 999; const int z = 99; char c1 = x; // OK, though it might narrow (in this case, it does narrow) char c2{x}; // error: might narrow char c3{y}; // error: narrows (assuming char is 8 bits) char c4{z}; // OK: no narrowing needed unsigned char uc1 = {5}; // OK: no narrowing needed unsigned char uc2 = {-1}; // error: narrows unsigned int ui1 = {-1}; // error: narrows signed int si1 = { (unsigned int)-1 }; // error: narrows int ii = {2.0}; // error: narrows float f1 { x }; // error: might narrow float f2 { 7 }; // OK: 7 can be exactly represented as a float int f(int); int a[] = { 2, f(2), f(2.0) }; // OK: the double-to-int conversion is not at the top level